Parallelization of CFD on DCAC System

Introduction
We've implemented a 2D CFD solver to simulate airflow patterns of a Data Center Air-Conditioning System and parallelized lid-driven cavity model with OpenMPI and Cuda.
Data Center Cooling
Data center is a specially designed space, which houses numerous servers with high power intensity. Therefore, data center requires cooling all year round. However, without proper airflow design of the air-conditioning system, it will take risks of failure due to high temperature zone. Therefore, CFD simulation is necessary for engineers to detect the potential problem due to bad air flow design. In order to detect the potential problem due to bad air flow design, com- putational fluid dynamic (CFD) simulation is necessary. Our 2D Navier-Stokes solver is aimed to predict the interior air flow patterns and temperature distri- bution with different inlet velocities and validate the results with Ansys. The simulation results can be used to help computer room air conditioning(CRAC) system designers to identify better CRAC configurations.
Theories
Computational Fluid Dynamics is using computing machinery to solve/simulate physical phenomena with fundamental theory in the field of fluid dynamic/mechanics. With the governing equations of fluid mechanics: Navier-Stokes (N-S) equations, one can simulate the flow patterns in a fluid space. With finite difference method, a quadrilateral mesh grid can be created. However, there are many other topological meshes, which can be categorized as structured mesh and unstructured mesh. Instead of finite difference method, finite difference volume is a dominant discretized method used in CFD package since unstructured mesh can be easily implemented with it. In addition, numerical flow simulation is a dominant method to solve the unsteady incompressible N-S equations. With this method, the continuous do- main is discretized and apply the discretized domain to the continuous N-S equations, namely a finite-dimensional problem. The simplest discretization of N-S equations is to use finite difference method to update the values of each cell until it converged.
Problem & Opportunity
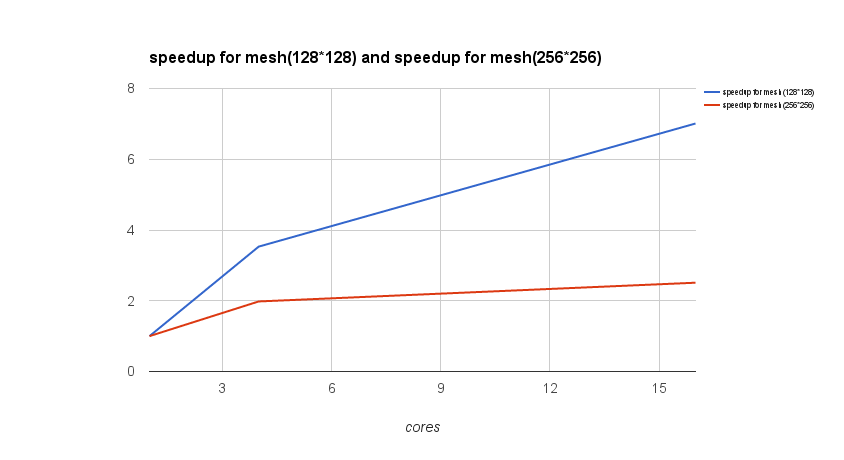
Since the finer mesh will increase the accuracy of CFD simulation, scientists ex- pect to reduce the mesh size. However, the computational cost will increase dra- matically as the mesh gets finer. Therefore, parallel computing becomes useful in CFD simulation. In addition, due to complex geometry and boundary condi- tions of data center air-conditioning system, it is usually a time-consuming task to simulate the airflow patterns inside the data center. Hence, our problem is to parallelize the serial version of simulating airflow patterns of the air-conditioning system in a data center. physical model and boundary conditions (data-center; lid-driven cavity) are shown in the following figure and the velocity boundary conditions are shown in the following table. Since the data center contains many racks, we just investigate the airflow patterns around one rack. In addition, since the geometry is symmetric, only half of the domain is calculated. In order to simplify the geometry, the lid-driven cavity model (without ob- stacle) was firstly developed to ensure the correctness after parallelization.
Our Approach
Before parallelizing data center air-conditioning system, we've parallelized the 2D simulation of lid-driven cavity using Cuda and MPI. The parallel speedup is to be measured with the baseline of serial version in C. In addition, the correctness is to be guaranteed with the Matlab version, which has already been verified with commercial software of Ansys Workbench. More details about our implementation is discussed later.
Details on Design & Implementation
Message Passing
For message passing algorithms, we followed the approach to divide the underlying domain Ω into subdomains Ω1,Ω2,Ω3,...ΩN and have each processor treat one subdomain. This first domain decomposition method was proposed by Her- rmann Amandus Schwarz. In our solver, we used overlapping subdomains. In each time-stepping loop, each subdomain is assigned to a processor and communicate with its neighbor processors or master processors when necessary.
Cuda Based method
The cuda based parallellization is implemented such that all the matrix related computation is done in the GPU memory. For all the for loop that is to update the matrix or matrix rows/columns, it can be computed in parallel in cuda threads without ordering restrictions. One exception is the Red-Black Gauss- Seidel parallellization step that is to be discussed more in detailed later. There are some other parts of the code that requires serialized computation, one is a sum of all the elements of a matrix, another is taking the max value of a matrix. The final implementation used third part cuBlas and thrust libraries for this. Multiple implementations are tried for improving this part of the computation and it turns out to be a significant part of cost of the whole simulation. We also use one optimization to improve cache performance. We write new values to one copy of the matrix in memory while reading from another stale copy of the matrix in memory. At the end of each iteration or where we need the new matrix, we swap the pointers to the two matrix. The Red-Black Gauss-Seidel parallellization is based on the idea that the update of a cell u[i][j] is based on the value of u[i-1][j], u[i+1][j], u[i][j-1], u[i][j+1]. From the graph below, we can find that for all the cells u[i][j], if i+j is odd, it only depends on the even indices. If i+j is even, it only depends on the odd indices. This makes it possible to update half of the matrix in parallel without ordering restrictions but still keeping the correctness. With Red-Black Gauss-Seidel parallellization, the most repeated computation part of the simulation can be significantly speeded up. For the max value of a given matrix, we tried using thrust max element function in the extrema utilities. We also tried cublas’s cublasIdamax function. We also implemented our own reduce based max element function. For the sum of a matrix, it is very similar to the max value function, we also used thrust reduce based implementation, cuBlas vector multiplication by creating a vector of all ones, and our own naive reduce based sum function. Other parts of the code can be executed in parallel without other special interference or change of logic.
Experiments
Environment Setup
Our C/C++ code should be able to run with different machines specs that has Nvidia GPU and cuda libraries installed or has MPI libraries installed. We cre- ated Makefiles that shoule be straight forward to run to generate the simulation results. No other special setup is required to run our code. However, CFD simulation is computationally heavy and will benefit from good performance multi-core GPU/CPU hardware. To measure the performance, we performed most of the tests and experiments on the latedays cluster. We also used a AWS g2.2xlarge with GPU instance to run our experiments. For more details, please refer to readme file in the source code. If running on CMU machines, PATH needs to be modified according to http://15418.courses.cs.cmu.edu/fall2016/article/4.
Experimental Evaluation